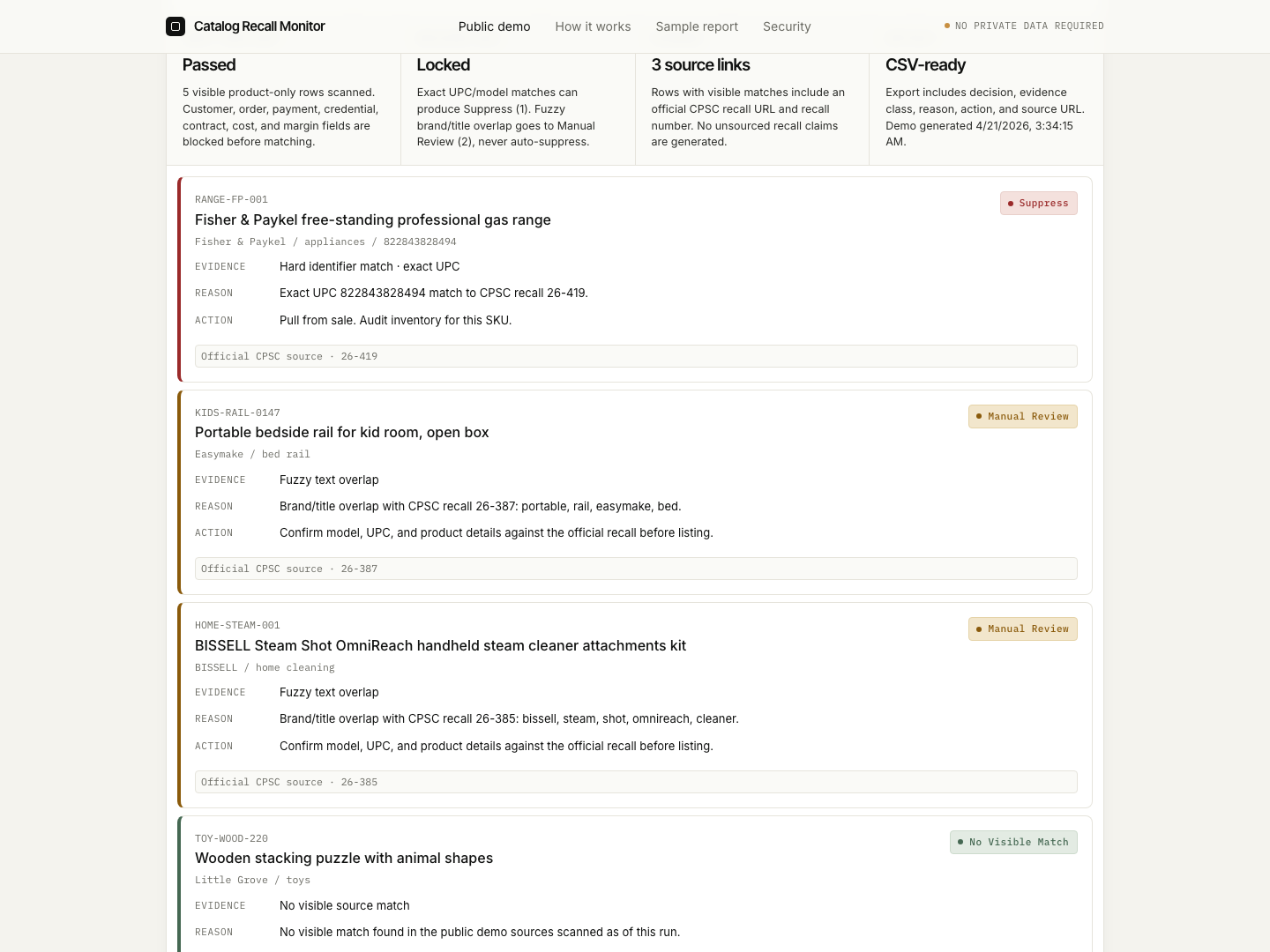
Public demo with audit trail.
Buyers can run synthetic resale rows first and see why exact evidence, fuzzy evidence, and no-visible-match rows are treated differently.
Catalog Recall Monitor is a CPSC-first recall review workflow for resale, recommerce, and safety-sensitive ecommerce teams. This packet shows the live demo, redacted-sample prep, source-backed report artifact, and the boundaries that keep the first test low-risk.
The problem is not whether AI can summarize one recall page. The problem is whether a team can repeatedly check messy catalog rows, keep fuzzy evidence out of automatic suppress decisions, link every visible match to an official source, and preserve a reportable trail of what was reviewed.
These are real screenshots from the public site. The point is not cinematic stock imagery; it is letting a buyer see the demo, data guardrails, and report artifact before sending a file.
Buyers can run synthetic resale rows first and see why exact evidence, fuzzy evidence, and no-visible-match rows are treated differently.
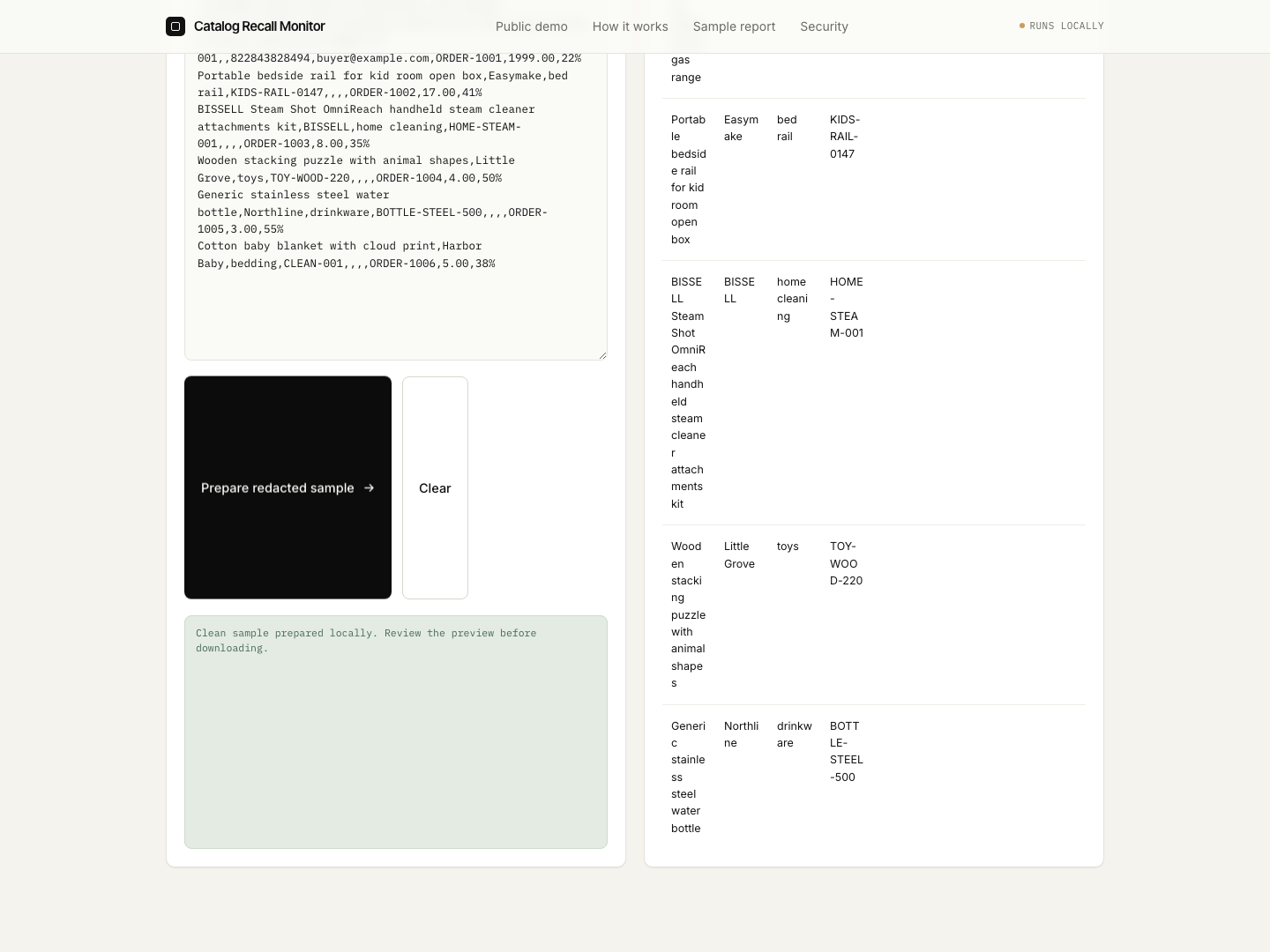
The cleaner keeps product fields, excludes obvious private columns, and helps produce the five-row sample we ask for first.
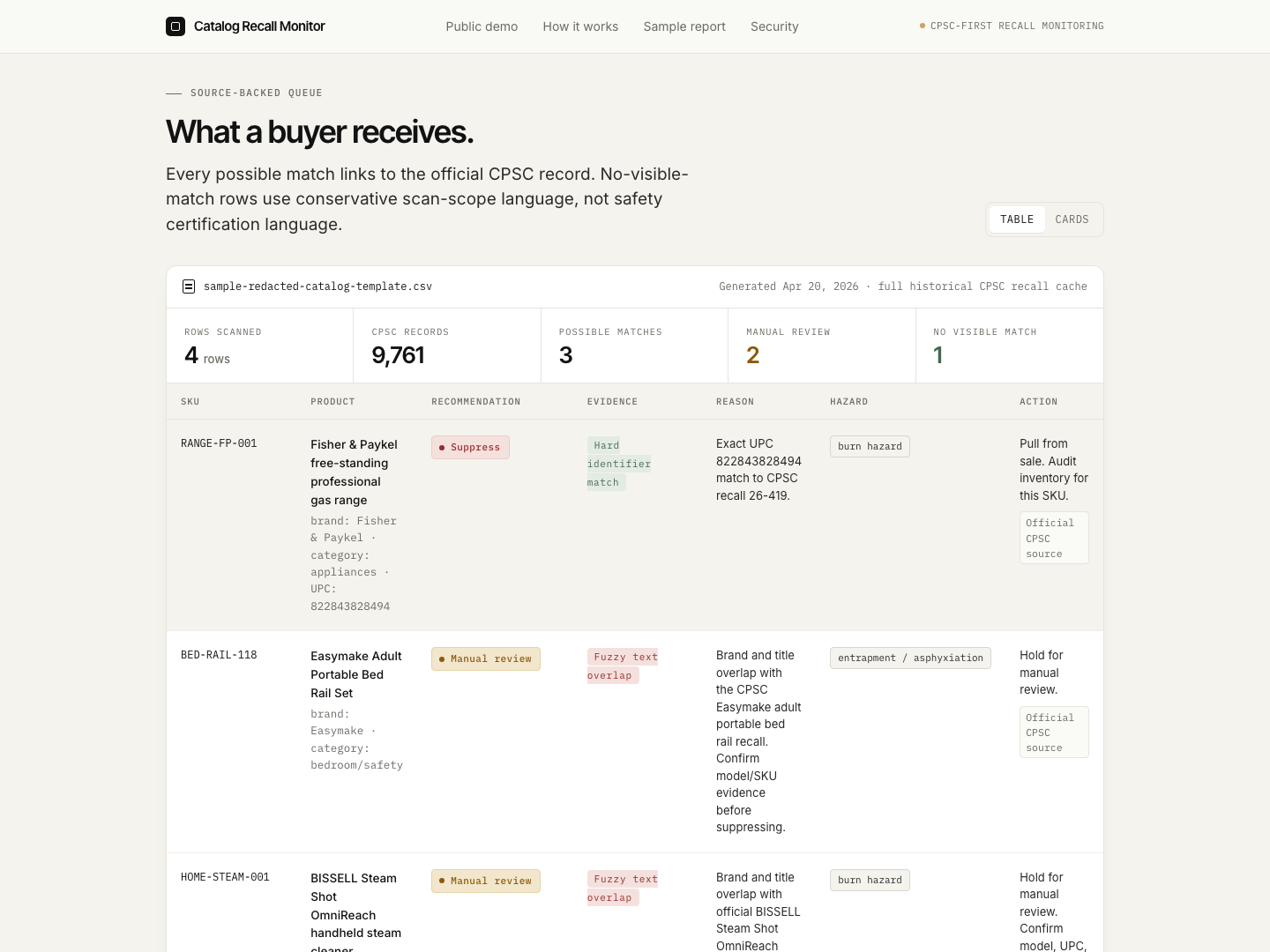
The buyer receives a source-backed suppress / manual-review / no-visible-match queue with reasons, actions, and official CPSC links.
The workflow explains what ChatGPT can do, what it cannot preserve, and why repeatable evidence matters for catalog operations.
This is the core reason the workflow is stronger than a broad chatbot answer. The report keeps uncertainty visible instead of converting it into false certainty.
Used for hard identifier evidence such as exact UPC or exact model-number evidence linked to an official CPSC recall.
Used when brand, title, category, or partial model text overlaps with a recall but needs a human check before action.
Used only to say no visible match was found in scanned official sources as of the scan time. It is not a product safety certification.
The first useful trust move is not payment. It is seeing whether a real operator is willing to send a tiny product-only sample and whether the report changes an operational decision.
No account, upload, card, or private data required.
The browser-only cleaner helps remove customer, order, payment, cost, and credential data.
The report shows reasons, actions, CPSC source links, and conservative decision language.
Recurring monitoring is only worth discussing after the first artifact proves it changes work.
The trust play is simple: show the live demo, show the real report, show the data boundary, and make the first buyer action tiny. No fake customers, fake certifications, or fake enterprise scale.